
Record Breaking Level3 Outage
Since Sunday’s Level3 outage nearly every customer or prospect we’ve spoken with has asked us what we’re doing to avoid that type of downtime or why CacheFly stood up so well against an issue that caused 3.5% of the internet to go dark.
I could tell you that our network is superior in every way from our competitors and therefore, we’re just better. But that would be disingenuous. We don’t peer with Level3 anywhere on our network. It’s not some calculated strategic move. Up until Sunday, around 10 UTC, they were considered to be one of, if not the most reliable provider of peering on the planet. We happen to have chosen other peering partners. Due to some Level3 employee’s human error, their entire system shut down, and with it, a great deal of the internet as a whole. Since we don’t peer with Level3 we had no direct impact and had a much smaller outage than any of our competitors. We saw about a .4% dip in our network availability compared to anywhere from a .7-30% from other CDNs. This was a combination of a lack of Level3 peering and the ability of our Anycast network to route traffic around outages.
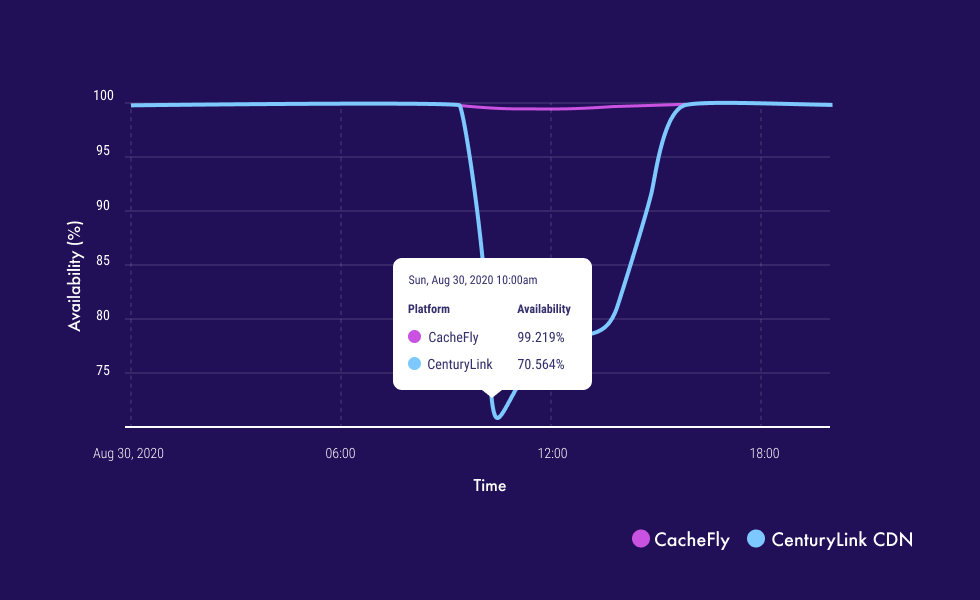
One of the marked differences between this outage and others we’ve seen was that as networks who peer with Level3 tried to bypass the problem by turning them off – the situation just got worse. As operators shut down the pipe, Level3 kept pushing requests turning 50-80% packet loss to 100% and blackholing traffic. I’m sure the atmosphere in NOCs around the globe was quite elevated as network engineers attempted to reroute traffic and activate failover to no avail. This is concerning on many levels and Level3 needs to rectify whatever caused the problem quickly in case of another error. Cloudflare does a great job of cataloging what the outage looked like for them and some of the troubleshooting here.
It’s worth noting that Anycast network’s seemed to handle the outage better than others, based on how we route our traffic. This helps to protect CacheFly and other Anycast CDNs from network failures as we don’t rely on DNS to route the traffic. Content on our network finds it’s way to the end-user even if the closest PoP to them is down. However, every single network impacted by this event had failovers in place. They just didn’t work, and there was nothing anyone outside of Level3 could do about it.
CacheFly’s CTO talks more about how the Level3 outage impacted the internet in his own blog post.
We’re all reeling from the largest internet failure in history and this is a good reminder to all of us that we can never be too prepared against unexpected outages.
Product Updates
Explore our latest updates and enhancements for an unmatched CDN experience.
Book a Demo
Discover the CacheFly difference in a brief discussion, getting answers quickly, while also reviewing customization needs and special service requests.
Free Developer Account
Unlock CacheFly’s unparalleled performance, security, and scalability by signing up for a free all-access developer account today.
CacheFly in the News
Learn About
Work at CacheFly
We’re positioned to scale and want to work with people who are excited about making the internet run faster and reach farther. Ready for your next big adventure?



